Talks · 18 June 2015 · Ian Malpass
Failure Is An Option
This is a transcript of a talk I gave at the Velocity Conference in Santa Clara on 28 May 2015. It’s transcribed from the video recording, but edited slightly for clarity.
I’m Ian, I’m a software engineer at Etsy. For those of you who don’t know, Etsy is an online marketplace for handmade and vintage goods, and I’ve been working there for about five and a half years now. Over the last five years we’ve been on a journey from sort of traditional working practices to a DevOps-style approach. It’s all been fascinating to be part of, but the thing that I’ve found most interesting—the thing that I always find I come back to—is how we’ve started to evolve the way in which we approach failure: how we understand failure, what we care about, how we deal with it. And it’s important. It’s how we learn: we learn from our failures.
What I’m going to talk about today is not a blueprint for organisations, it’s not some magic bullet where failure magically becomes your friend. I’m just going to talk about how Etsy approaches failure, how our philosophies and our ideas around it translate into the day-to-day work, into our tooling, and into our approaches for building stuff.
But before I get into that, I’m going to present three truths. At least I will claim them as truths. You are free to argue. The first of those is: you will create bugs. We’re not perfect. Well-trained, intelligent, motivated engineers still make bugs. We’re building complex systems, and with any system—any code that’s sufficiently complex to be useful—it’s impossible to be certain of being bug-free. And it takes a long time to even get close. We don’t have time.
You will build the wrong thing. Our understanding of our markets, our understanding of our requirements, is imperfect. And our markets and our requirements may well change while we’re developing things. It’s not just that people are moving the goalposts, the whole pitch can be shifting. And that extra time that we took to be sure of being bug-free? Well, everything changed again. And we still have bugs.
And the third truth. Kind of by definition: you will not foresee the unexpected. You just won’t, it’s by definition. Weird stuff happens that you just can’t anticipate. We’re not acting in a bubble. Outside factors—internal factors for that matter—will always tend to complicate things. And when they do, or when you build the wrong thing, or when you have bugs, there is a cost. When we fail, there are costs associated with that.
It costs money. The easiest one to spot. The site goes down, you can’t do business. People can’t pay our sellers money. People can’t sign up to sell, people can’t sign up to buy. But, we could have capacity planning failures. If you have some sort of capacity planning failure, all of a sudden your AWS bill goes through roof, or you’re having to buy a ton of servers and ship someone down to the datacenter to rack them in short order.
It costs time. It costs time to go back and fix those bugs. It costs time to go back and build the thing that you built wrong. You have to rebuild it. It costs staff time that you can’t afford.
It costs data. Data loss, the thing that tends to keep us up at night.
It costs customers. “This site sucks, I’m never going back to this, it’s broken all the time.”
It costs us credibility. It’s hard to even attract customers if you’re failing all the time. And from an engineering point of view, it’s also hard to attract good people to work with you. If you get a reputation for having your site on fire all the time, it’s hard to attract the good engineers that are going to make your company a better place and push you forwards.
But I said that failure is inevitable. Bugs happen. Building the wrong happens. Failure to anticipate happens. We are… doomed. We should go home. We’re done.
But while failure is inevitable, expensive failure is not. How do we make small failures rather than big failures? How do we fail in private rather than in public? How do we fail tactically rather than strategically? How do we reduce the cost of failures?
So the typical response to this inevitability of failure is to erect barriers. We’re going to double- and triple-check everything. We’re going to implement processes, we’re going to implement procedures, we’re going to limit the ability of any individual to do harm. All this gives you is deniability. “I followed the rules.” The site still caught fire.
Instead, what we want is speed. This is an aptly-named conference, Velocity. It may seem a little counter-intuitive, but speed and the resulting flexibility makes you safer in an uncertain world. It sounds a little dangerous, and it is dangerous in the same way that power tools are dangerous. Used well, used skillfully, a power tool will let you get a lot of stuff done very efficiently. But you can also cut off your thumb.
So our general philosophy is that if we spend a lot of time and effort hiring good people (and we do) we should get out of the way and let them get stuff done. And that requires trust. We trust people to do the right thing. If we trust people to act responsibly and in the best interests of our customers and the best interests of the company and the best interests of our community—if we trust them to do that, they do. If we trust developers to take responsibility for their code in production and not just throw it over the wall at Ops, they do. If we trust Ops to talk openly and frankly about the impact of development work on the site, and their resulting on-call schedules and capacity planning, they do. And it feels good to be trusted.
And this gives is flexibility. Speed and flexibility. We get rid of these rigid timelines, we get rid of the straitjacket procedures and the hoops that you have to jump through, and that gives us space to come up with solutions to problems. We can respond quickly, we can respond effectively.
So, we just say “go fast, we trust you!” and we’re done! No… unfortunately not. But, when you accept failure, accept that it will happen, and when you accept that speed and flexibility are the way to respond to this, then you have to start crafting your tooling and your approaches to deal with that.
So let’s look at how we look at bugs. Bugs are sort of the thing that tend to exercise us most commonly as engineers, and the core of what we want to do is deploy. We want to deploy often. With continuous deployment, the way we do it at Etsy, we can deploy master at any time with minimal fuss, and minimal ceremony. That’s the core of what gives us speed and flexibility.
We have Deployinator. It’s a web-based tool, it’s a very open process. It started off as a bunch of scripts for Ops to try to wrestle the code onto the site but slowly over time it evolved into this web-based process. And it’s open to everyone. There are no gatekeepers. It’s not limited just engineers, it’s not limited to Ops or some priesthood of release engineers, it’s open to anyone. We have designers, we have product managers who will deploy their own code. They don’t need to wait for an engineer to act as an intermediary, they can just get on and do their jobs.
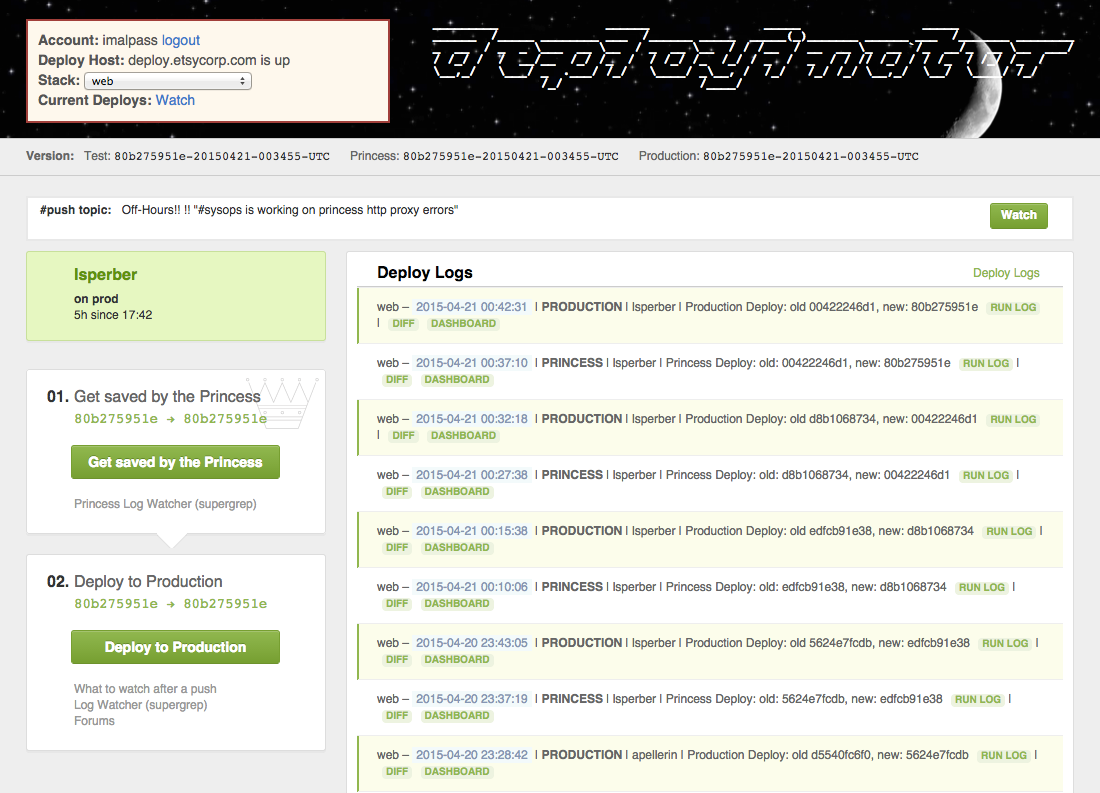
If you look, you’ll see it’s as you’d expect: we log who did what and when and what happened. But you’ll also notice up at the top, there’re things like the #push topic—we orchestrate all of this through IRC in the #push channel. I took this screenshot in the evening, and the IRC topic says “Off Hours”. So although we can deploy any time, day or night (and we do), we tend not to deploy in the evenings, when there aren’t so many people around. We can, if we need to, but we prefer not to. It makes it a little safer if there are more people in case things go wrong. But also, it’s nice to encourage people to go home and do other things, rather than be pushing all night.
So if we have this easy process for deploying—we make it fast, we make it easy—the result of that is that we do it often. And because we do it often, we’re pushing small chunks of code. We build something small and we deploy it. We build the next something small and we deploy it. And that has a big impact on code reviews. So code reviews are a core part of what keeps us safe. We’re reviewing each other’s code. And that takes time and effort, but it’s time and effort that pays off, because you’re learning through code reviews. You’re learning about the people’s code that you’re reviewing, you’re learning from their approaches to solving problems. And they’re learning from you, they’re learning from your expertise. And these small chunks are are way easier to review. If I give you a 50 line diff, you’ll probably find ten bugs and a handful of architectural problems. If I give you 500 lines you’re like “Yeah, it’s fine, ship it. We’re good, go ahead.”

So if you look at a typical deploy—this is maybe on the slightly smaller side, but it’s not atypical—it’s 19 files, six people, about 240 lines of code changed, so about 40 lines of code each. It’s not much code per person. That’s easier to review, easier to reason about, and if there’s a failure, then it’s limited to a much smaller surface area. And typically, instead of having to revert, we actually roll forwards. It’s as quick to find the problem, fix it and push it out again as it is to push a revert. So we don’t lose our momentum. We keep moving forward. We solve our problems and we can do it quickly because we have continuous deployment. So we’re reducing the time to resolve the problem, we’re reducing the time it takes to get to our code working. It’s reducing the cost of failure.
But, I’m getting ahead of myself, because we really don’t want the bugs to even get to production in the first place. That’s unfortunate when that happens. The core of avoiding bugs is testing. We’re going to make sure our code works, as best we can. There is very little manual testing at Etsy as a distinct job function. We have QA engineers and they’re amazing, but we tend to use them on areas of high risk, so things like our apps which are harder to do continuous deployment with, or things like checkout where money is on the line, we’ll put dedicated QA resources there to really give it a good kicking and dig in with their specialist skills. But beyond that, QA becomes the responsibility of all engineers, and QA as a job function becomes part of a partnership, a collaboration. We work with QA engineers to understand their skills, to learn from them, and become better testers ourselves. So we have QA as a partner, as a collaborator, rather than QA as a gatekeeper. Or, in the event of failure, QA as a blame sponge. “It’s QA’s fault. They passed it.” No, it was your bug.
Similarly Security. Like QA, they’re collaborators, they’re partners, not gatekeepers. QA and Security help to keep us safe through their specialist knowledge, but they’re sharing that with us. We’d rather get their insight early and fix the problems rather than get it right before we deploy and suddenly have a panic because there’s some major security flaw. We want to partner with Security, we want to partner with QA, rather than have this sort of gatekeeping, adversarial relationship, and that’s going to keep us safer in the long run.
And of course we have automated tests, that’s not a surprise. But even here there are some interesting trade-offs. Because, the more automated tests you have, and the more complex they are, the longer they take to run. And that gives a lower bound on the number of deploys you can do. If your tests take an hour to run, you’re going to have a maximum of maybe seven, eight, nine deploys a day. And if the site catches fire and you want to push, you have to make a choice. Either you’ve got to let it burn for an hour (not desirable) or you’ve got to skip the tests (also not desirable). What we want is for the tests to be fast.
And to do that, we have two approaches. One is that we throw hardware at it. We break the test suite up and we split it across a bunch of very fast test machines. That works very well for speeding things up; we can get the test run times down quite well. But when we started instrumenting a lot of this, we took a look at it, and we looked at the distribution of times for each individual test, and we found that a very small number of tests contributed to the vast majority of the run time. And we looked at them, and we deleted them. Sacrilege. But, in truth, when we looked at them, they’re not actually making us much safer. They’re these arcane tests for some weird regression that’s probably not going to happen, but we’re having to pay this time every time we want to deploy, every time we want to run the tests. Which remember, if we’re deploying fifty times a day, adds up quickly. The amount of safety it gives us is minimal compared to the cost of slowing us down.
Similarly we have no tolerance for flaky tests—a test that just fails at random. Most of you who have dealt with automated tests will have encountered these things. But if you have a test that flakes 1% of the time, if you’re pushing 50 times a day that’s going to happen every two days, on average. And when it happens, it completely derails the push. You’re ticking along nicely, all of a sudden tests are red, something’s gone wrong. Panic. Go and look. OK, what failed? Is this a flaky one? Is it OK? Are we sure it’s actually flaking this time and it’s not actually a real failure. You’ve got doubt, you’ve got uncertainly, you’ve got to dig into things, you’ve got to run the tests again, you’ve got to double check stuff, and your deploy goes to hell. And all the people lined up to deploy after you, they’re also stuck. So it completely ruins the flow of things. And you can guarantee that this happens right when the site’s on fire and you want to deploy right now. So if a test flakes, it either has to be refactored to make it not flake, or it has to be deleted. The cost of the test, because it’s flaky, typically outweighs its benefit. This is a pattern. Does the cost of something outweigh the benefit, the extra safety that it’s giving us?
But really, we don’t want tests to fail at all when we’re deploying, because it derails the push, so we have to try. Try is our way of being able to run the tests fast for developers. We don’t want to run them on our VMs, they’re a little bit underpowered to be honest and the tests take ages to run. Instead we run the try command, which takes your diff, sends it to the try servers, they apply it to master as if you were deploying and they run the tests, essentially simulating what it will be like when you come to deploy. And when everything is green, you can have some measure of confidence that when you deploy the tests are going to pass. Test failures in the deploy queue are comparatively rare because of that. And that not only minimises the risk of bugs, it’s minimising the risk of us not being able to deploy at will when we want to.
So, we’ve run try, everything’s green, we commit our code, we hit the button, the automated tests start running, and we have a Princess. Princess is the name we gave to a kind of pre-production environment. It’s basically all your new code but with production backends. It’s exactly what our members will see when we actually get to production. We are able to poke around while all the automated tests are running. We can poke around and just verify that things do actually work in production. We’ll see exactly what our members are going to see when it goes out. It’s a final manual check—remember, QA aren’t gatekeepers. It’s your responsibility—your code, your responsibility—so we can poke around on Princess, make sure that everything’s working, everything’s doing what we expect it to do, and then when the automated tests are done we can push to production.
We do that some manual testing in production, but we also have our graphs. We measure everything. We have a ton of metrics. We can watch those and see what happens. If things go wrong, graphs will usually move. We summarise those on dashboards.

Here’s a small subset of one of our deploy dashboards, around end-user errors. You can see some interesting features. Three-Armed Sweaters, which is the name given to a particular image on one of our error pages—if that spikes, something’s going wrong. Screwed Users is an evocatively-named metric, but that’s actually an aggregate metric. It’s the sum of a bunch of different metrics, each representing a member having a bad experience, a bad time, some sort of error. We add them up and if it moves, we know that something is going wrong. We can dig into other graphs on other dashboards to work out exactly what, but these are our canaries in the coal mine. You also might see a faint grey line there—that’s a historical average. It not only shows if things are moving, it shows what we typically expect. Is it about in line with the norm or is it deviating. And you’ll see the vertical lines, those correspond to deploys. If you’ve got a graph that’s ticking along nicely, you hit a vertical line, a deploy, and it suddenly spikes or it suddenly drops, you know something’s going wrong, you can be pretty sure it’s related to the deploy. Correlation is not causation, etc., etc., but you can kind of assume it.
So we have the deploy dashboard which is a specifically curated set of graphs, the sort of top-line metrics like user-facing errors, number of checkouts, number of logins, basically a good barometer of the health of the site. But we also make it easy to build and deploy custom dashboards, so individual teams or individual engineers can build their own dashboards to monitor the things they care about. So when they’re pushing out features they can monitor their own dashboards as well as the deploy dashboard and they can see if something’s going wrong,
And we also have logs. We have a web-based UI called Supergrep which streams live logs so we can see, if something goes wrong, all of a sudden Supergrep is full of errors. We know something’s gone wrong, but also those error logs contain things like stack traces. We can link them to GitHub so we can see very quickly what’s going wrong. So graphs and logs are not only changing our mean time to detection—we can see when something’s gone wrong because the logs are filling up or the graphs are moving—it also allows us to respond more quickly. We can reduce the cost of failure because we can dig in, find where in that small changeset the problem came from, fix it, and roll forward.
Now, this all sounds well and good, small changes pushed out regularly, that’s lovely. But it’s not actually how we build features, right? We don’t actually build them little bit by little bit. And that’s true. We have this idea of dark code: code that isn’t executed. So rather than pushing code out and it being immediately live, it goes out and it’s not executed. We’re shipping the code incrementally but we’re not necessarily shipping the features incrementally. So we’ll push it out behind a feature flag. A feature flag is typically an if-statement. It checks a config file: if it’s enabled, execute this block of code. If it isn’t, don’t touch it. That code is dark. It’s not going to affect the end-user experience at all. So we can isolate our new code and have it happily living in production before it’s ever switched on. Individual engineers can override those flags so you can go in and test in production before it gets to anyone else. You can just go in and override the flag.
When it comes to switching it on, it’s not an all-or-nothing thing, it’s not a boolean. We can just send it to 1%, a little sliver of traffic. It’s great for testing performance. If your databases start catching fire at 1%, imagine what would have happened if it had been 100. It’s much better to expose 1% of your traffic to a bug than 100%: you’re reducing that potential cost of failure. There’s no rush, you can go to 2%, maybe you’ll skip on to 10%. Pushing a config is very quick, you’re just deploying one file and running a small set of tests to make sure the config file is safe, so it’s a really quick process. We keep going, we get to 50%, and if something does go wrong, if something goes bang, there’s a bug, I didn’t see it, there’s a problem: it’s OK. Take it back down to 0%. Switch it off. It’s been off in production for ages already, you can be confident that it’s off when you tell it it’s off. You can be confident that you’ve cut the bug back off again, you’ve reduced the cost of failure. And eventually, of course, you get to 100% (hopefully) and that’s the nearest thing we have to a launch. But we’re not deploying a brand new version of Etsy, it’s a new feature or a revision of an existing feature. It’s often a bit of an anticlimax because it’s been in production already for ages. OK, on with the next thing.
But what if we built it wrong? We don’t have bugs, it’s just the wrong thing. We’re not really a “Minimum Viable Product” type organisation, but we do tend to build small things and iterate on them, and that’s reducing the risk of building the wrong thing. Are we completely off? Are we actually solving the problem we’re meant to be solving? Continuous deployment makes this easy because you can iterate and test and tweak and you know that you’re not hooked into some three- or six-month release cycle where you have to get it right otherwise you’re stuck for another three months, six months.
But not only can we switch feature flags on for a slice of traffic, we can switch it on for particular groups. So we can expose our colleagues to the new code. They can be our guinea pigs, and they’re really good guinea pigs because as you can imagine our colleagues are using the site all the time. We all have a nasty habit of spending too much money on Etsy, and many of us are also sellers, so we have a good idea of what works and what doesn’t, we have a good idea of what’s meant to happen. We get not just feedback like “oh this is buggy” but “this doesn’t actually solve the problem” or “this completely messes up my workflow”. We can get this feedback and we can get it in private before we even get out to our sellers or our buyers.
And even when we want to get out to the public, it’s not an all-or-nothing thing. We can set up groups of people that our buyers and sellers can opt into. “We’re testing out a new feature. Join this group and you’ll get access to it. Tell us what you think.” We get that feedback. If it’s awful, if everything’s broken, they can leave the group and they’re back to the original experience. So it minimises the cost of failure for them. They get to come and give us feedback and we learn a great deal from them, but if something’s bad, if the experience is bad or buggy, they can back out of it at no cost.
When I was talking about ramping up and got to 50%, some of you may have thought “that sounds remarkably like A/B testing” and you’d be right. A/B testing is a very common technique for working out “are we building the right thing?”. We take a hypothesis, we build something to test it, and we show it to a subset of our visitors and we compare the two populations. We can measure things, be it conversion rate, bounce rate, whatever metrics you care about you can measure those and you can look and see how the two populations differ. Does it make a difference? Does it make the right sort of difference or does it make things worse? Try to understand why, rinse, repeat, get better.
But we still have the problem of the unexpected. Although we can’t foresee the unexpected, we can expect it. We know that something weird is going to happen, this is inevitable. Speed and flexibility are your friends. Fast, easy deploys allow you to react quickly when the unexpected happens. They allow you to recover.
So, for example: I used to work on Etsy’s Risk Engineering team. We have an on-site messaging system called “Convos” and it’s a known thing that sometimes we get some spam through it, but it’s usually pretty low-level and our existing spam technologies were handling it. Until one day we started to get a new attack, much more sophisticated than any of the ones we’d seen before. Much higher volume and it was getting past all of our defences. This was a problem. We don’t want our members exposed to spam, that’s a bad experience.
But what we could do was look at it and say “what’s the simplest thing we can do to stop this attack now?”. To which the answer was that they have this particular string in them, it’s clearly part of the spam message. If we push out a thing that says “if it contains this message, it’s spam, ban the account, don’t send the message”. Alright, very simple change, very easy to reason about, very easy to have confidence that it’s going to do what we expect and not have any unintended side effects. We wrote it, pushed it out. It took maybe twenty, thirty minutes from us realising that we had to do something to actually getting this simple thing pushed out, and it stopped the attack. It didn’t stop it for long. The spammer noticed, of course, reconfigured the attack and started up again. But it took about an hour, maybe, to notice, during which time we’d had a bunch of conversations about “what’s the next simple thing we can do?”. We already had that ready, we pushed that out, and it stopped the attack again. We did this for probably a day or two, off and on, them reconfiguring the attack, and us getting gradually more and more sophisticated, having more and more time to make good decisions about what we wanted to do.
And we ended up with a very robust set of spam-fighting measures and we ended up with the attack stopping. Without continuous deployment, without the ability to do this sort of cat-and-mouse back-and-forth, we would have either had to switch off Conversations (not good, it’s going to impact on how our sellers and our buyers use the site) or we’d have to leave Convos on and just deal with the spam. Neither of those alternatives are particularly appealing, and we didn’t have to deal with them because we had continuous deployment.
We also have the ability to have partial failures. So if, for example, the Conversations database blows up, we can actually switch off Conversations using our feature flags. We keep feature flags in production so we can switch features off and on as need be. So we can switch off Convos and yes it’s not good because people can’t send their messages, but they can still buy, they can still give our sellers money. Our sellers can still manage their shops, they can continue to do business. It’s not ideal, it’s a degraded experience, but it’s better than a total failure. Similarly, if we rely on third parties and they tell us they’re going to have some scheduled maintenance (or they don’t tell us they’re going to have some unscheduled maintenance) we can wire that particular bit off, we can reduce that surface area. The site doesn’t work as well as it should do, it doesn’t work the way we want it to, but it’s not broken.
But despite all of this we still fail. Despite our best efforts. All of the stuff that we’re doing reduces the risk, it reduces the cost, but it doesn’t eliminate it. But if you accept that that’s going to happen, then you also need to accept that you need to learn from it. The skateboarder Rodney Mullen said “the best skaters are the best fallers”. We want to be really good fallers. We want to be able to learn from our mistakes so that we don’t do that again. They way in which we do that is through blamelessness. The culture of blamelessness at Etsy is core to how we’re learning from failure, and it’s an entire topic all by itself far outside the scope of this talk, but at the core if something goes wrong we’ll have a “blameless postmortem”. We’ll review what went on, we’ll ask what happened. What did people do? Why did they make the decisions that they did? We assume that they’re acting in good faith. We assume that they’re not expecting to take the site down, they just did. Why was there that mismatch between what they expected to happen and what actually happened?
From that we learn. We get these remediation items that come out of our reviews. What do we need to do to make ourselves safer in the future? What can we learn? These are very important. One of the things that we try to avoid though is the knee-jerk response “let’s implement a new process”. Remember that thing with automated tests. Does the extra friction, does the extra time it takes to do a particular process actually contribute safety, or does it (by slowing us down) increase our risk?
We share what we’ve learned. We share it widely. We get these amazing emails where someone’s built an experiment and they’re like “We expected that it would increase conversion by 10%. It didn’t touch conversion but sign-ups dropped by 25%.” Oh. It’s a big failure. We’ve completely failed to understand some part of the site, some interaction, and these are emailed out to the whole company and people are discussing why it failed. We’re not just learning from it, and learning from it publicly (at least publicly within the company), we’re normalising the idea that failure happens and that learning is important. Together, we can understand our systems better for the future.
To the extent that we actually celebrate failure. We have an annual award: The Three-Armed Sweater Award. I mentioned the three-armed sweater that’s on our error page. We actually had an Etsy seller knit us a literal three-armed sweater and it’s awarded each year to the individual or team who breaks the site most spectacularly while attempting to do something important. As an example, my team won the inaugural Three-Armed Sweater when a system that we’d built went kind of a little bit rogue and started banning all of the admin accounts on the site, all of my colleagues were like “oh, we’ve been banned!” Sorry…. It was a bad day. It was not a good time. But that system still exists at Etsy. We fixed the problem that caused it to do that, and now it’s—day-in, day-out—part of our risk mitigation strategies, and it’s keeping our members safe. We were doing something important, we were building something important. We made a mistake and it was unfortunate, but we learned from that mistake.
Similarly the t-shirt that I’m wearing today—the four stars and a horse—we actually printed up t-shirts to celebrate a bug because it was sufficiently awesome. Somehow the half-star glyph started rendering on some platforms as a horse. (One of the platforms was guessing emoji and apparently “half-star” is close to “horse”.) Obviously we fixed the problem, but we also had this amazing email thread with hundreds of messages with horse-based puns and then we screen-printed t-shirts. We celebrate failure, especially the most spectacular ones.
It’s really about celebrating pushing the envelope. If you never push the envelope, any progress you make will be slow. And you’ll still have failures. If you do push the envelope, you are going to have failures and some of them might be spectacular, but if we celebrate these spectacular failures we make sure that everyone understands that we shouldn’t be timid, we shouldn’t be fearful. Our tooling provides us with the ability to recover from these failures (even the spectacular ones).
Mark Zuckerberg said “move fast and break things”, which is fine, but I think my colleague Dannel Jurado said it better:
Move Fast and Break Things But Then Fix Them Because You Broke Them and You Can Move Fast Come On You’re Better Than This™
— Dannel Jurado (@DeMarko) August 16, 2013This is the Etsy Way.
And with that, I leave it to you. I’ve basically described this idea, how we take this idea, this fundamental idea “speed makes us safe”, and I’ve worked through some of the ramifications of this: how it impacts day-to-day, what decisions we make as a result. This is where we are today, it’s not where we were last year, it’s certainly not where we were five years ago. It’s a process, we’re always iterating, we’re always improving, we’re finding new things to tweak. If you’ve sat here and you’re looking at things and you’re disagreeing with me, that’s great because it means that you’re thinking about why you disagree with me. You’re articulating why you disagree. It’s helping you define your own goals, your own philosophies, and helping you make clear the trade-offs that matter to you, the trade-offs that you think are going to make your organisation better and that are going to reduce your risk of failure. And for that, I wish you the best of luck.
Thank you.